Overview
This project builds a real-time human pose imitation system for the NAO humanoid robot. A webcam feeds MediaPipe Pose, geometric reasoning extracts 3D joint angles for the shoulders, elbows, and head, and those angles are streamed over a TCP socket to a NAOqi-side process that replays them on the robot — frame by frame — using setAngles and angleInterpolationWithSpeed.
On top of the live behavior, the same pipeline logs a synchronized human↔robot dataset (45,120+ entries) where each detected gesture is paired with both the commanded and the measured NAO joint angles — opening the door to imitation learning and motion-transfer research.
Why NAO?
NAO is a 58 cm humanoid with 25 DoF distributed across head, arms, hands, legs, and pelvis. Each joint is reachable through the NAOqi API (ALMotion), which exposes both instantaneous (setAngles) and time-interpolated (angleInterpolationWithSpeed) commands. Mathematically, the kinematic chain is described in the Denavit–Hartenberg convention; the forward kinematics map joint vectors θ to Cartesian end-effector poses, and inverse kinematics solve the reverse mapping under joint and balance constraints.

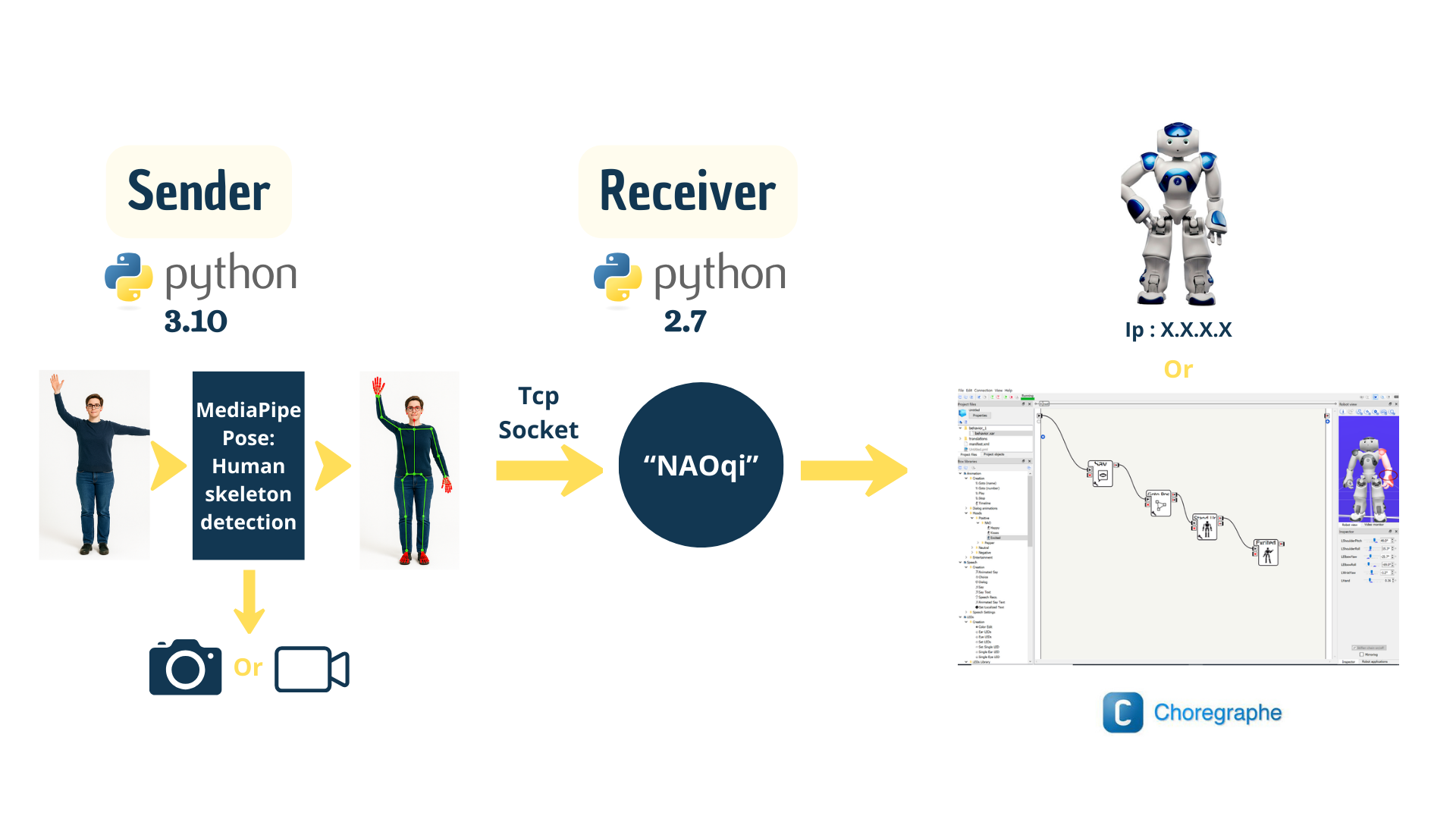
System Architecture
The pipeline is a clean sender ↔ receiver split — vision lives on one side, robot motion on the other, and they only exchange small JSON messages over TCP. This decoupling keeps the Python 3 / MediaPipe world separate from the legacy Python 2.7 NAOqi runtime.
Sender (Python 3.10)
- MediaPipe Pose extracts 33 body landmarks per frame (head, torso, arms, legs).
- A library of gesture detectors (
clapping.py,flipKick.py,thinking.py, …) classifies poses from geometric conditions on the landmarks. - A stabilizer layer (HOLD_FRAMES, HOLD_TIME, COOLDOWN) suppresses jitter.
- Each stable gesture is shipped over TCP as a JSON payload:
cmd,run_id,event_id, plus four landmark variants (raw / normalized / visibility / trusted).
Receiver (Python 2.7 + NAOqi)
- A socket listener accepts each command and routes it to a motion handler.
ALMotionexecutes either an instantaneoussetAnglesor a blockingangleInterpolationWithSpeed, depending on the gesture.- Every commanded target is paired with the actual sensor reading and written to disk.
Pose Estimation with MediaPipe
MediaPipe gives us 33 3D landmarks per frame. The detection layer uses three building blocks built on top of them:
Euclidean distance — used for “wrists close together” (claps, hand-on-head, etc.):
d_ij = √( (x_i − x_j)² + (y_i − y_j)² + (z_i − z_j)² )
Vertical ordering — “wrist above elbow” tells you the arm is raised:
y_wrist < y_elbow
Joint angle from three landmarks — the elbow / knee / shoulder bend:
θ = arccos( (p_shoulder − p_elbow) · (p_wrist − p_elbow)
/ (‖p_shoulder − p_elbow‖ · ‖p_wrist − p_elbow‖) )
Because everything is relative (vectors and ratios), the detectors are invariant to user height and camera distance.
Gesture Vocabulary
The system ships with a curated set of recognizable gestures, each defined by simple, human-interpretable geometric conditions:
| Gesture | Condition | NAO Behavior |
|---|---|---|
| CLAP | Wrists within ε at the same vertical level, double-contact in 2 s | Alternating ElbowRoll for applause |
| FLIPKICK | Left knee above hip + left wrist above shoulder | LHipPitch, LKneePitch, head tilt |
| THINK | Right wrist near head + left arm ≈ 90° + legs straight | Right hand to head + slow head nod |
| YAAAY | Both wrists above elbows + above shoulders + knees bent | Both arms up, knees bend |
| STOP | Arms crossed at chest height | Arms crossed (blocking) |
| TAP FIVE (L/R) | One arm raised vertically | Side-specific arm raise, speed 0.15 |
| GRABBING | Torso lean forward + hand close | Hip pitch + close hand + reset |
| LOOK FAR | Hand near face + head turned | Hand shading face + head yaw |

Stabilization
Real-time landmark detection is noisy, so several layers smooth the signal before it can fire a robot motion:
- Hold frames — a gesture must persist for ≥ N frames (typ. 4) before being confirmed.
- Hold time — minimum stable duration (≥ 0.35 s) to filter transients.
- Cooldown — once fired, a gesture is suppressed for C seconds (CLAP uses 3 s) to avoid double-triggering.
- Trusted landmarks — points with MediaPipe visibility below a threshold are zeroed out.
- Exponential smoothing —
L̄_i(t) = α·L_trusted(t) + (1 − α)·L̄_i(t − 1)(typ. α = 0.2).
Together these turn a flickering raw stream into clean gesture commands.
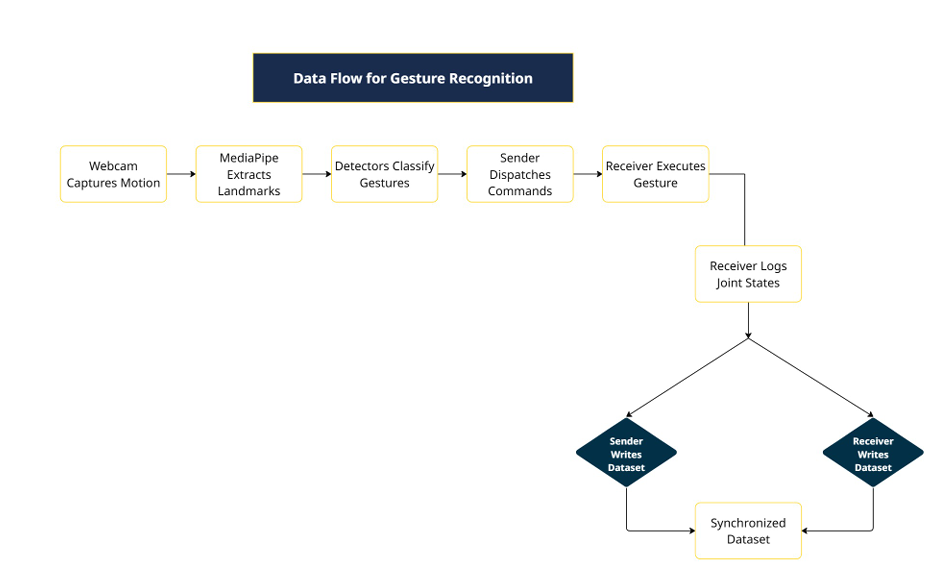
Synchronized Dataset
A central goal of the project is the dataset, not just the live show. Every gesture event is logged on both sides of the socket, indexed by a run_id (per-session) and event_id (per-gesture):
Normalization & filtering (made the data usable)
Before merging, landmarks are normalized by a torso reference point and a scale factor (shoulder width):
L̃_i(t) = ( L_i(t) − L_ref(t) ) / ‖ L_scale(t) − L_ref(t) ‖_2
This way a tall and a short person yield comparable values, and changes in camera distance are absorbed automatically. Low-visibility landmarks are zeroed via:
L_trusted(t) = L̃_i(t) if v_i(t) ≥ τ
0 otherwise
Results
The merged log contains 45,120 paired records, covering FLIPKICK, CLAP (multi-phase, blocking), STOP, YAAAY, TAP FIVE (L/R), and GRABBING.
Execution fidelity (commanded vs measured joint angle)
| Gesture / phase | Method | Mean |err| (rad) | Max |err| (rad) |
|---|---|---|---|
| CLAP rep 1 phase A | angleInterpolation (blocking) | 0.038 (≈ 2.2°) | 0.100 (≈ 5.7°) |
| CLAP rep 1 phase B | angleInterpolation (blocking) | 0.014 (≈ 0.8°) | 0.023 |
| FLIPKICK keyframe | setAngles (non-blocking, mid-motion) | 0.670 (≈ 38°) | 2.178 |
Two clear takeaways:
- Blocking interpolation gives sub-degree to low-degree fidelity when the motion has time to settle — exactly what we want for a clean dataset.
- Non-blocking snapshots inflate “error” because the robot is sampled mid-trajectory — useful for studying transient dynamics, not for steady-state accuracy.
Recognition
- CLAP and YAAAY were consistently recognized across users.
- More subtle gestures (THINK, LOOK FAR) occasionally suffered from partial occlusions, but the visibility-based filtering and HOLD/COOLDOWN windows kept false positives low.

Challenges & Solutions
- False positives / overlapping gestures — solved with multi-frame validation, visibility thresholds, and per-gesture suppression rules.
- Clap detection — naive wrist proximity was too sensitive; replaced with a double-contact-within-2s rule plus a 3 s cooldown.
- Sender/receiver synchronization — solved by stamping every payload with
run_id+event_id, which makes log merging trivial. - Latency vs fidelity — blocking calls are accurate but slow; non-blocking is responsive but noisy. The dataset records both
methodandspeedso downstream analyses can pick a side.
Tech Stack
- Python 3.10 (sender) / Python 2.7 (receiver, required by NAOqi)
- MediaPipe Pose — body landmark detection
- NAOqi SDK —
ALMotion(setAngles,angleInterpolationWithSpeed) - OpenCV + NumPy — frame capture and vector math
- TCP sockets + JSON — inter-process communication
- NAO V6 humanoid
Watch the Imitation
Future Work
- Larger gesture vocabulary — waving, pointing, handshakes, multi-step interactions
- Learning-based detection — replace the heuristic detectors with a model trained on our own dataset
- Latency-aware control — predictive blends of blocking + non-blocking actuation
- Cross-robot transfer — port the dataset and pipeline to other humanoids (Pepper, Reachy)
- HRI studies — measure not only execution accuracy but also user trust and intuitiveness
Contributors
- Imad-Eddine NACIRI
- Oussama Errouji
Takeaway
Real-time imitation is the easy half — the dataset is the contribution. Pairing MediaPipe landmarks with measured NAO joint feedback turns a teleop demo into a reusable benchmark for imitation learning, motion transfer, and gesture-grounded HRI.