Overview
This was my graduation project (PFE) for the Robotics Engineering degree, conducted as a research internship at LITIS Laboratory, Rouen University (Feb – Jul 2024), as part of the Inclusive Museum Guide (IMG 2021–2025) initiative.
The goal: design and build a real-time AI voice assistant that helps visually impaired visitors experience the Bayeux Tapestry and other artworks through natural spoken conversation — answering scene-level questions, giving rich contextual descriptions, and doing it all locally, free, and open-source.
“A nation that does not know its history cannot shape its future properly.” — Arabic proverb that framed the project’s motivation.

Objectives
- Develop a robust, free, open-source conversational agent that provides scene descriptions on demand.
- Evaluate the system using standard NLP / speech benchmarks (WER, RTF, IRA, SFA, BLEU, USS…).
- Iteratively improve the quality through visually impaired user feedback.
System Architecture
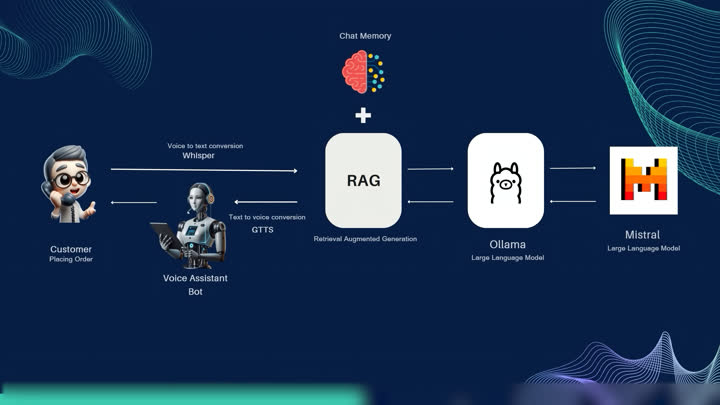
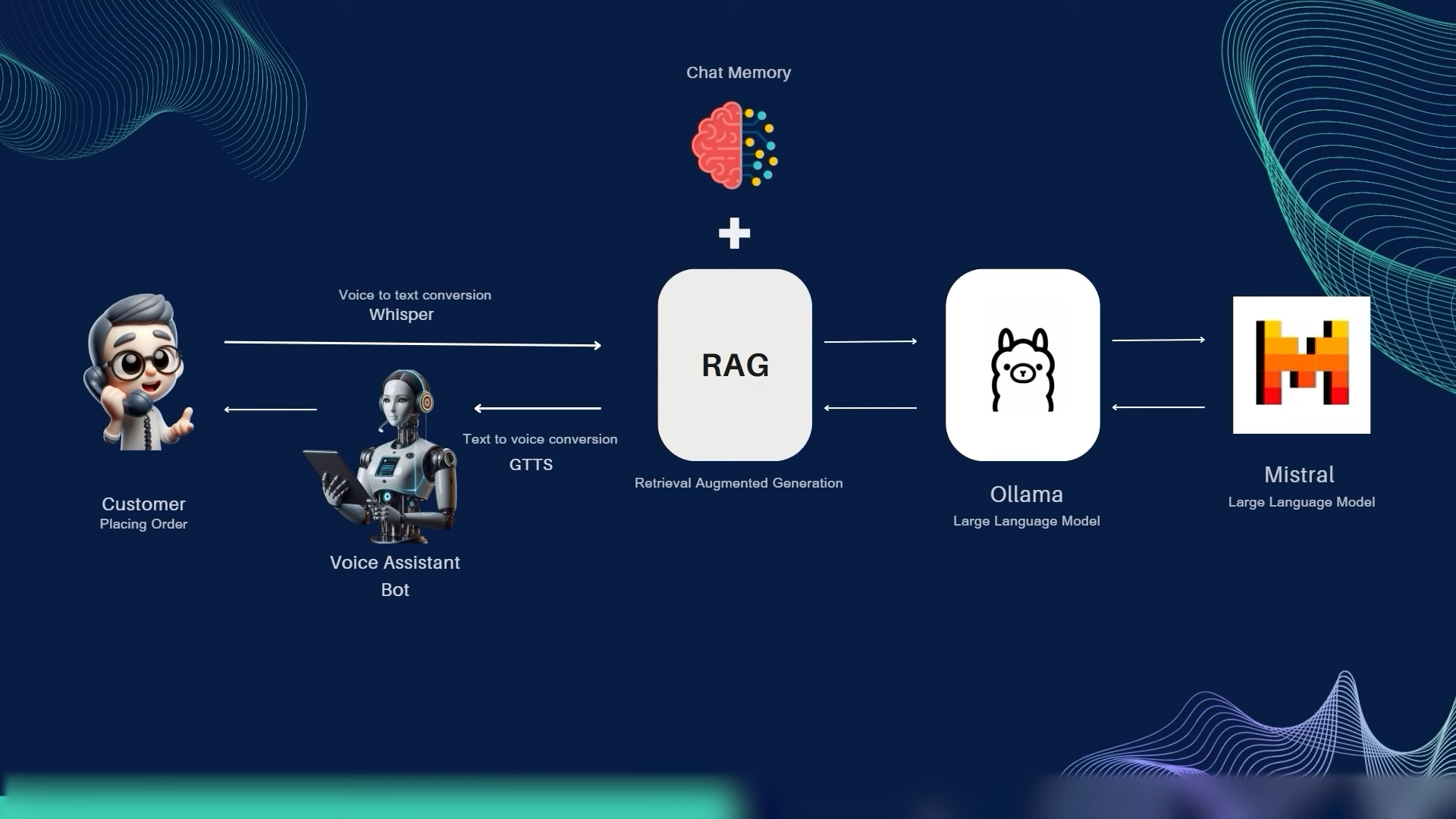
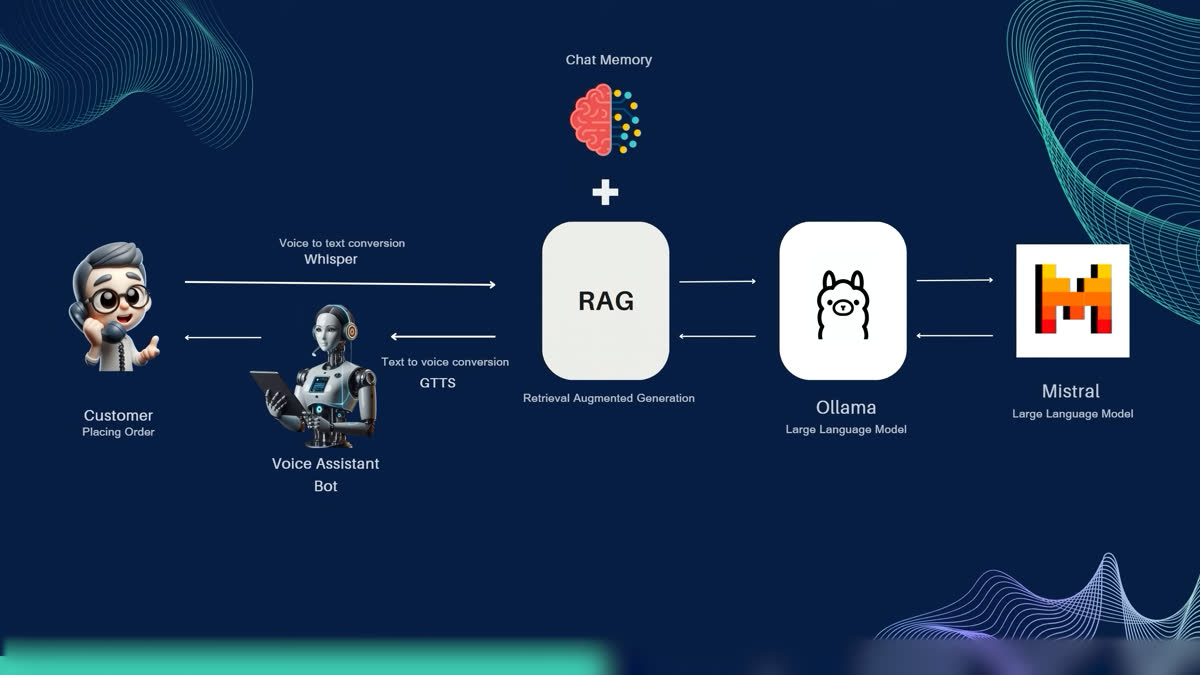
The pipeline is a classic but carefully-tuned STT → NLU → RAG → LLM → TTS loop, running entirely on local hardware:
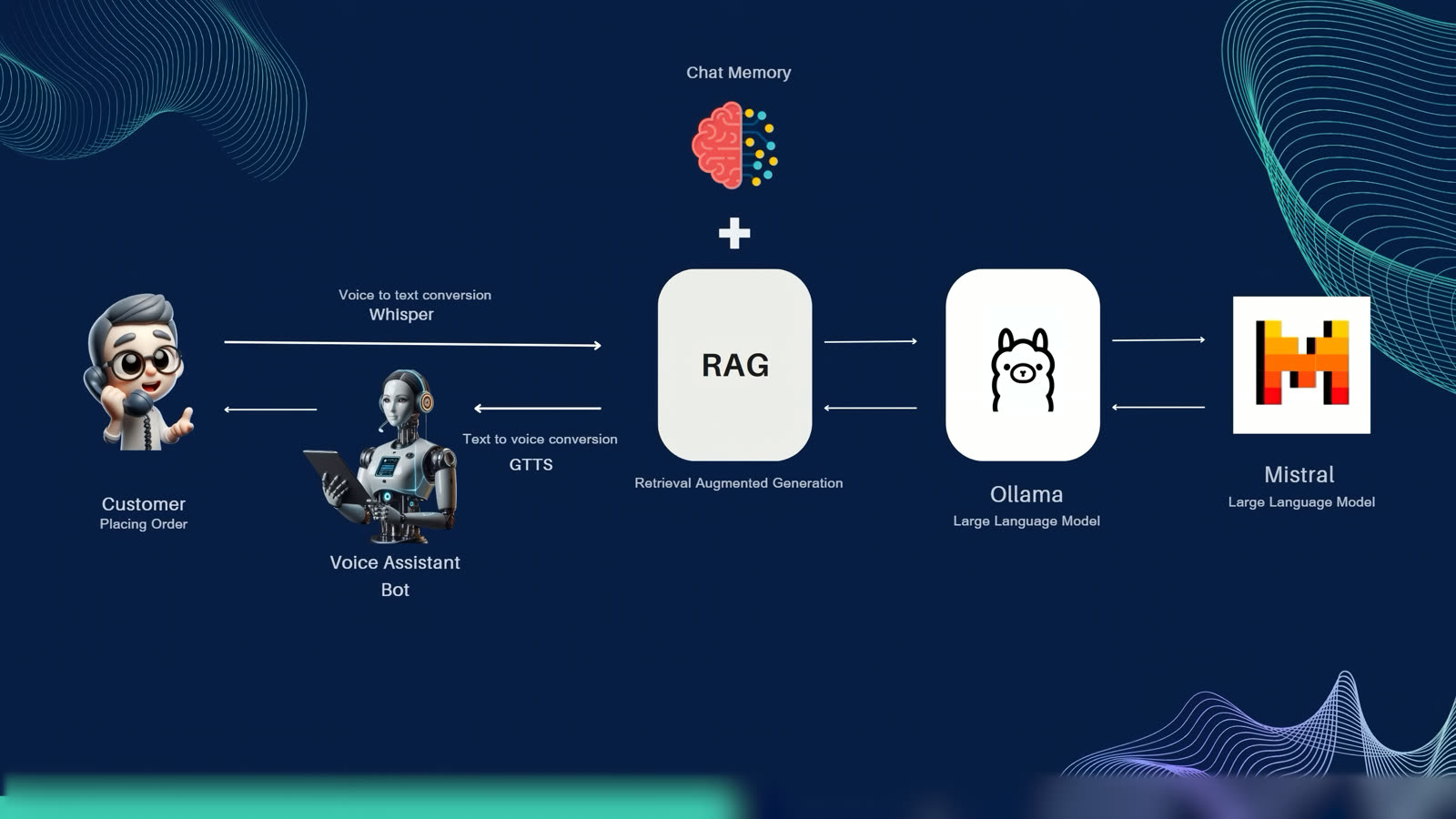
- Speech-to-Text:
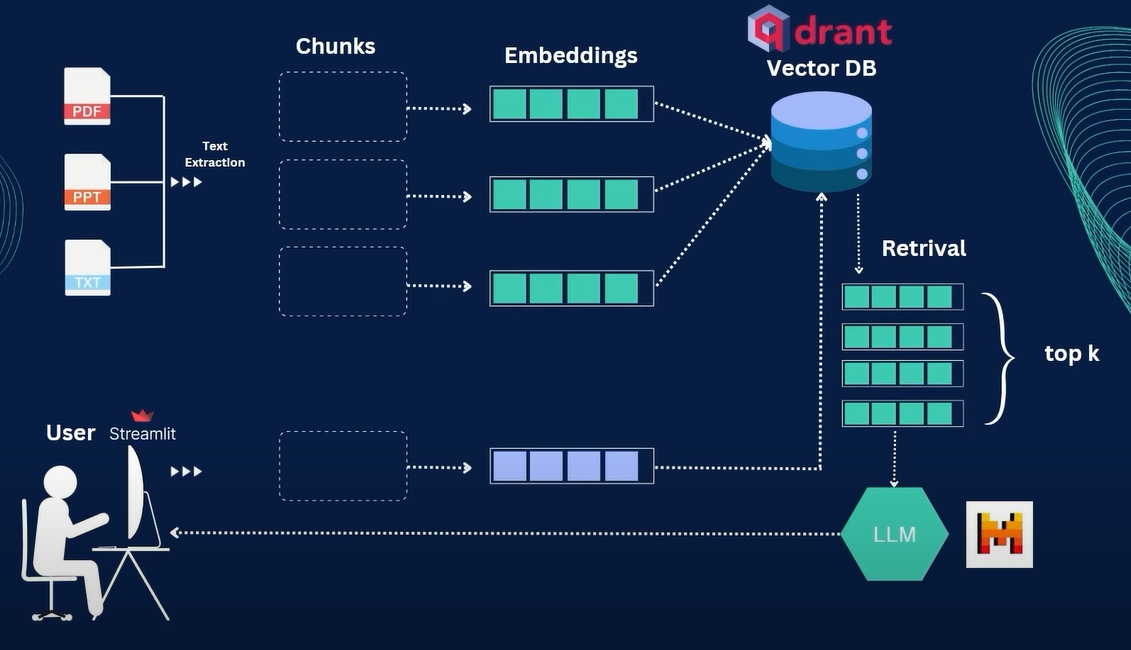
Faster-Whisper(SYSTRAN) running Whisperlarge-v2on GPU — chosen over DialogFlow / Wit.ai for privacy and zero cost. - Embedding:
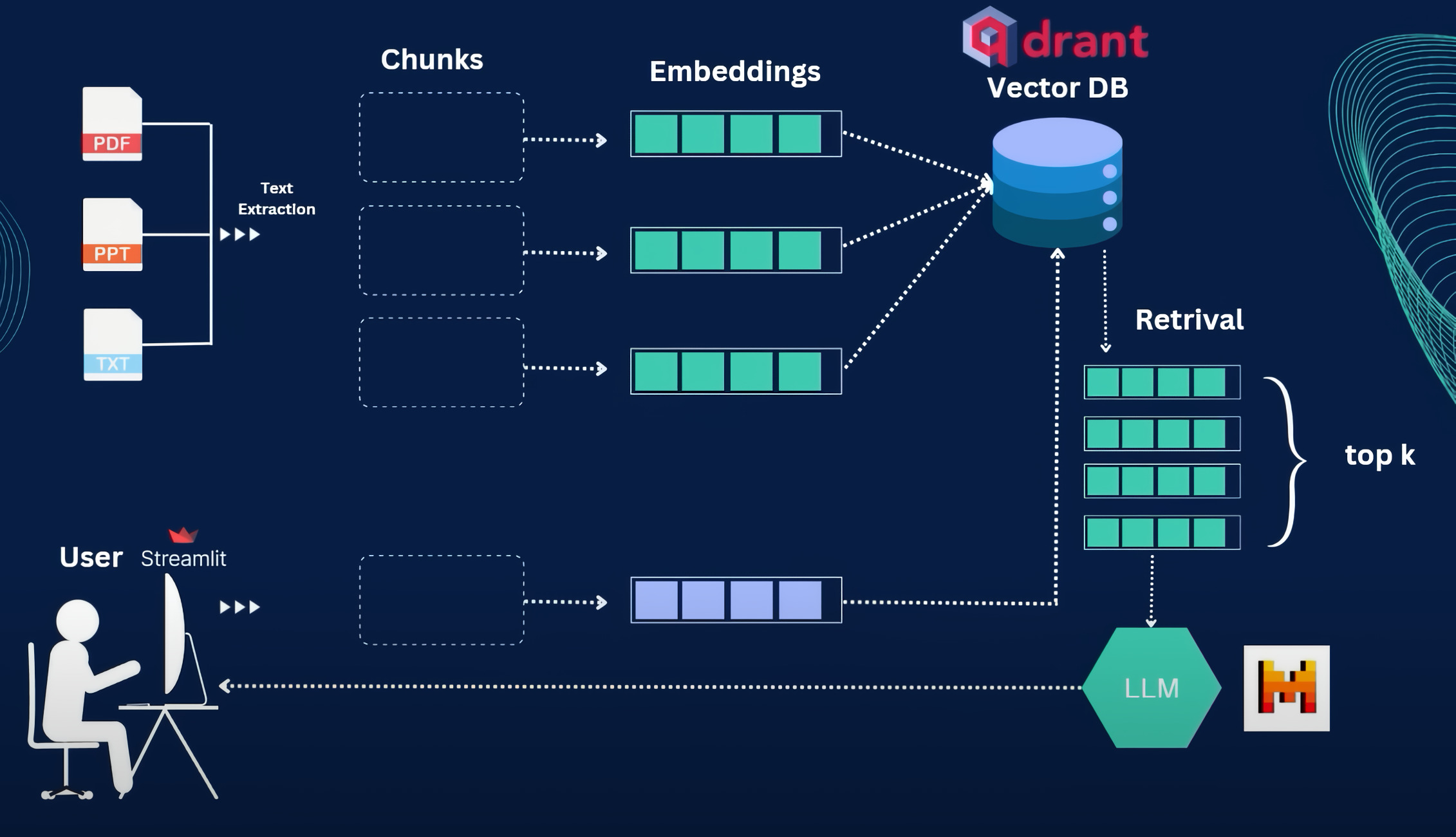
nomic-text-embedfor semantic search across the knowledge base. - Vector store: Qdrant for retrieval.
- LLM: Meta Llama 3 (released April 18, 2024, 4.1 GB) as the primary local model, with Mistral as an alternative — both served via Ollama.
- RAG: Retrieval-Augmented Generation over a curated knowledge base built from Bayeux Tapestry scene descriptions, historical context, and museum metadata.
- Text-to-Speech: gTTS (Google Translate TTS) for free, multilingual, high-quality speech synthesis.
Why this stack?
Two approaches were considered early on:
- Frameworks & platforms (DialogFlow, Rasa, Wit.ai) — fast to build, but not free, not private, and hard to extend.
- Custom DL/NLP architecture — higher effort, but full control, full privacy, and far better quality.
The custom architecture was chosen. The breakthrough enabler was RAG + open LLMs: existing rule-based or closed-KB chatbots often fail when the answer isn’t explicitly in their database and tend to sound artificial. RAG combined with a modern LLM produces coherent, fluid, contextually grounded responses — and once Llama 3 dropped in April 2024, the “reliable LLM must be run in the cloud” blocker was finally gone.
Example interactions
Evaluation
Testing was conducted at LITIS Lab, U2 Room 1.57 over June 24–28, 2024, with 6 participants (2 professors, 2 PhD students, 2 interns) wearing masks to simulate visual impairment. 100 questions were used: 70 specific to the Bayeux Tapestry scenes, 30 general (history, politics, everyday topics).
| Component | Metric | Result |
|---|---|---|
| Speech recognition | Word Error Rate (WER) | 7.89 % |
| Speech recognition | Real-Time Factor (RTF) | 0.83 |
| NLU | Intent Recognition Accuracy | 96.2 % |
| NLU | Slot Filling Accuracy | 91.1 % |
| Response generation | BLEU score | 0.89 |
| End-to-end | Response time | 5–8 s |
| End-to-end | Task completion rate | 92.4 % |
| End-to-end | User Satisfaction Score | 3.8 / 5 |
The system meets or exceeds the target thresholds on almost every metric — the main area to push further is response latency, which is largely bound by on-device LLM inference.
Challenges
- Paid models vs. the “100 % free & open-source” constraint — solved by Whisper + Llama3 + gTTS.
- Local deployment of a reliable LLM — unblocked by Llama 3’s release mid-project.
- Compute budget for real-time STT + LLM inference — required careful model sizing.
- Recruiting visually impaired testers for UX feedback.
- AI moving fast — kept the stack under constant review.
- Python dependency hell — familiar pain, managed with pinned environments.
Presentation (scrollable)
The full PFE defense presentation is embedded below — scroll or use the PDF controls to navigate through all slides directly from this page.
Open the presentation in a new tab · Download PDF
Perspectives
- Portable embedded version visitors can carry around the museum.
- Multilingual support for international audiences.
- Contextual memory across turns for more natural dialogue.
- Emotion recognition to adapt tone and empathy.
- AR/VR integration for tactile & immersive feedback.
- Beyond museums — schools, public services, healthcare navigation.
Supervisors
- Dr. Christèle Lecomte, Dr. Katerine Romeo, Pr. Cecilia Zanni-Merk, Dr. Abdellatif Ennaji (LITIS Laboratory, Rouen University)
- Pr. Alae Ammour (home university supervisor)
Takeaway
“Empowering individuals through technology is not just a goal; it’s a journey towards a more inclusive and accessible world.”
This project shows that a carefully engineered pipeline of open components can match the quality of closed, paid services — while respecting privacy, cost, and accessibility as first-class requirements.